
Wstęp
W pierwszej części z serii „SDS czyli storage o wysokiej dostępności” przyjrzeliśmy się rozwiązaniu GlusterFS. Ten artykuł to druga część tej serii poświęcona budowie klastra Ceph.
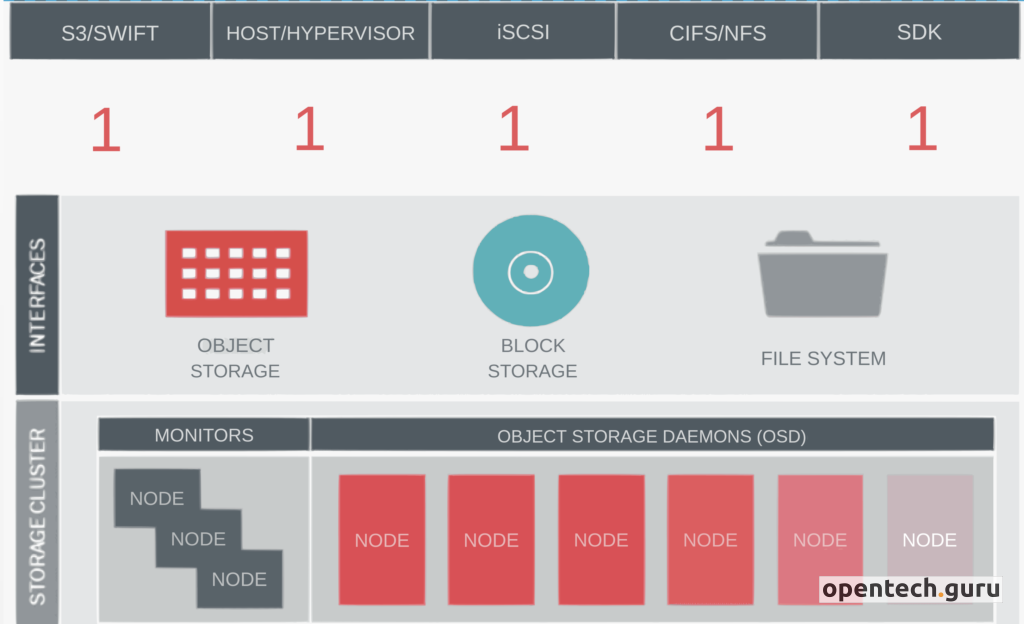
Ceph to rozproszony system plików i platforma zarządzania pamięcią masową, zaprojektowany w celu zapewnienia wysokiej dostępności, skalowalności i wydajności w przechowywaniu danych. Projekt Ceph został zapoczątkowany przez Sage’a Weil’a w 2004 roku jako część jego doktoratu na Uniwersytecie Kalifornijskim w Santa Cruz.
Głównym celem stworzenia Ceph było stworzenie systemu pamięci masowej, który potrafi zarządzać ogromnymi ilościami danych w sposób niezawodny i bez pojedynczych punktów awarii. Ceph jest zaprojektowany do pracy na standardowym sprzęcie, umożliwiając elastyczne skalowanie zarówno pojemności, jak i wydajności poprzez dodawanie nowych węzłów do klastra.
Klaster Ceph udostępnia trzy główne typy danych:
- Ceph Block Storage (RBD): Jest to system blokowy, który umożliwia tworzenie wirtualnych dysków blokowych. RBD jest wykorzystywany głównie w środowiskach wirtualizacji i chmur obliczeniowych, takich jak OpenStack.
- Ceph Object Storage (RADOS Gateway): Ceph Object Storage umożliwia przechowywanie danych w formie obiektów. Jest zgodny z interfejsami API S3 i Swift, co pozwala na integrację z aplikacjami korzystającymi z tych protokołów.
- Ceph File System (CephFS): CephFS to rozproszony system plików zgodny z POSIX, który umożliwia przechowywanie i udostępnianie plików w klastrze Ceph. CephFS przechowuje dane plików i metadane w oddzielnych pulach RADOS.
Ceph zdobył szeroką popularność wśród firm i organizacji potrzebujących skalowalnego i wysoce dostępnego systemu pamięci masowej, a jego rozwój jest obecnie wspierany przez społeczność open source oraz firmy takie jak Red Hat.
W niniejszym artykule omówimy proces instalacji i konfiguracji klastra Ceph, składającego się z sześciu serwerów 3 x Dell PowerEdge R740 oraz 3 x Dell PowerEdge R640. Serwery te zostaną skonfigurowane z odpowiednimi sieciami oraz urządzeniami dyskowymi, aby zapewnić optymalne działanie klastra.

„Ceph jest zaprojektowany tak, aby sam się naprawiał i zarządzał, co oznacza, że może radzić sobie z awariami i konserwacją bez interwencji człowieka.”.
— Sage Weil, twórca Ceph
1. Wymagania Wstępne
Na wszystkich nodach będziemy używać systemu Ubuntu Server 22.04. Jest to jeden z systemów oficjalnie zalecanych przez Ceph i moim zdaniem jego konfiguracja jak i późniejsze działanie jest najmniej problematyczne. W przypadku zaawansowanej konfiguracji sieci w systemach z rodziny CentOS/Alma/Rocky, choć wydaje się to niemal niemożliwe – bywają pewne problemy.
Przed przystąpieniem do instalacji Ceph, należy upewnić się, że wszystkie serwery mają zaktualizowane wersje BIOS oraz firmware w dokładnie tej samej wersji. Można to sprawdzić i zaktualizować korzystając z narzędzi dostarczonych przez Dell, takich jak iDRAC.
Sieci Cluster oraz Public powinny być zaprojektowane z wykorzystaniem osobnych kart sieciowych. Rozdzielenie tych sieci pozwala na lepszą izolację ruchu, co zwiększa wydajność i niezawodność klastra Ceph.
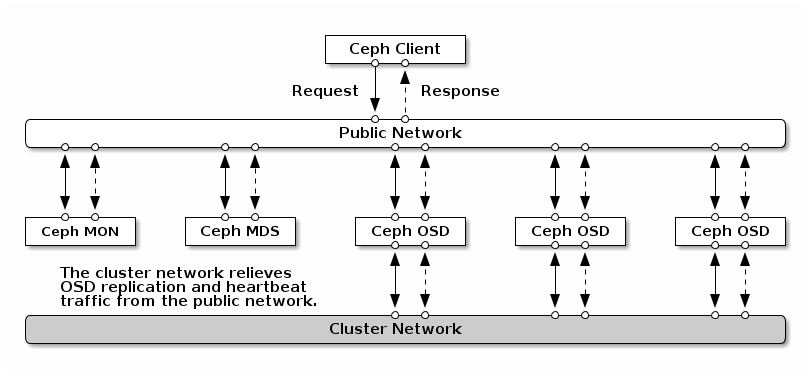
- Sieć Cluster jest używana do komunikacji między węzłami Ceph, takimi jak wymiana danych OSD, synchronizacja monitorów itp.
- Sieć Public jest używana do dostarczania danych klientom oraz zarządzania klastrem.
W celu zapewnienia pełnej redundancji rozwiązania musimy posiadać dwa switch połączone w jeden stack oraz karty sieciowe z dwoma interfejsami sieciowymi połączonymi w bond. Najbardziej odpowiedni tryb bondingu dla zapewnienia wysokiej dostępności i redundancji to mode=4 (802.3ad, LACP – Link Aggregation Control Protocol). Umożliwia on dynamiczne łączenie kart sieciowych i współpracuje z kompatybilnymi switchami. Opis konfiguracji switchy nie jest częścią tego artykułu.
Zalecana prędkość kart sieciowych:
- Cluster Network (Sieć Klastra):
- Zalecana prędkość kart sieciowych to co najmniej 10 Gb/s. Sieć klastra powinna być szybka i mieć niskie opóźnienia, ponieważ od niej zależy synchronizacja danych między węzłami. W przypadku większego ruchu pomyśl nad siecią SFP28, QSFP+ lub QSFP28.
- Public Network (Sieć Publiczna):
- Zalecana prędkość kart sieciowych to również co najmniej 10 Gb/s, zwłaszcza w środowiskach produkcyjnych o dużym obciążeniu. Dla mniejszych środowisk testowych 1 Gb/s może być wystarczające, ale nie zaleca się tego w środowiskach produkcyjnych.
2. Topologia Sieci
2.1 Adresacja
Klaster Ceph będzie korzystać z dwóch sieci:
- Public Network (sieć publiczna): 192.168.40.0/24
- Cluster Network (sieć klastra): 172.20.0.0/24
Adresy IP poszczególnych nodów zostały przypisane w następujący sposób:
| Node | Public IP | Cluster IP | Role |
|---|---|---|---|
| node1.ceph.lab | 192.168.40.211 | 172.20.0.101 | OSD |
| node2.ceph.lab | 192.168.40.212 | 172.20.0.101 | OSD |
| node3.ceph.lab | 192.168.40.213 | 172.20.0.101 | OSD |
| node4.ceph.lab | 192.168.40.214 | 172.20.0.101 | MON, MGR |
| node5.ceph.lab | 192.168.40.215 | 172.20.0.101 | MON, MGR |
| node6.ceph.lab | 192.168.40.216 | 172.20.0.101 | MON, MGR |
2.2 Konfiguracja DNS
Dodajemy rekordy A oraz RevDNSy (rekord PTR) dla wszystkich nodów.
Instalacja klastra Ceph nie wymaga bezwzględnie serwera DNS, ale jego obecność może znacząco ułatwić zarządzanie i konfigurację. Kilka kuczowych punktów dotyczących roli DNS w klastrze Ceph:
- Rozwiązywanie nazw hostów: Każdy węzeł w klastrze Ceph musi być w stanie pingować inne węzły za pomocą ich krótkich nazw hostów. Można to osiągnąć poprzez konfigurację pliku
/etc/hostsna każdym węźle lub poprzez użycie serwera DNS, który zapewnia rozwiązywanie nazw hostów - Monitor Lookup przez DNS: Klienci i demony Ceph mogą korzystać z rekordów
DNS SRVdo wyszukiwania monitorów Ceph. Jest to opcjonalne, ale może być przydatne w bardziej złożonych konfiguracjach. - Ceph Object Gateway: Jeśli planujesz używać Ceph Object Gateway z subdomenami w stylu S3 (np. bucket-name.domain-name.com), konieczne będzie dodanie rekordu wildcard do serwera DNS oraz odpowiednia konfiguracja w pliku konfiguracyjnym Ceph.
- Redundancja DNS: Jeśli zdecydujesz się na użycie DNS do rozwiązywania nazw hostów, ważne jest, aby serwer DNS miał odpowiednią redundancję, aby zapewnić ciągłość działania klastra w przypadku awarii serwera DNS.
Po konfiguracji domen sprawdzamy komunikację każdego noda z każdym, pingując nazwę domenową np: ping node1.ceph.lab
2.3 Jumbo frames
Na wszystkich urządzeniach sieciowych (karty sieciowe oraz switche) ustawiamy MTU na 9000.
MTU 9000 oznacza, że maksymalna ilość danych, które mogą być przesłane w jednym pakiecie Ethernet, wynosi 9000 bajtów. Standardowa wartość MTU dla Ethernetu to 1500 bajtów. Jumbo frames są często używane w sieciach, gdzie przesyłane są duże ilości danych, takich jak sieci magazynowe (np. iSCSI, NFS) oraz wirtualizacja (np. vMotion).
W przypadku systemu Ubuntu Server konfigurujemy MTU w netplan.
3. Konfiguracja dysków
3.1 Tryb HBA
W naszych serwerach konfigurujemy kontroler RAID do pracy w trybie HBA.
Tryb HBA (Host Bus Adapter) jest zalecany w przypadku konfiguracji dysków dla Ceph z kilku powodów:
- Bezpośredni dostęp do dysków: W trybie HBA każdy dysk jest widoczny jako osobny urządzenie, co pozwala Ceph na bezpośrednią kontrolę nad każdym dyskiem. To umożliwia lepsze zarządzanie i optymalizację wydajności oraz monitorowanie stanu dysków za pomocą narzędzi takich jak SMART
- Unikanie narzutu RAID: Korzystanie z kontrolerów RAID może wprowadzać dodatkowy narzut, który może obniżać wydajność. W trybie HBA dyski są prezentowane bezpośrednio do systemu operacyjnego bez dodatkowej warstwy abstrakcji, co minimalizuje opóźnienia i zwiększa wydajność.
- Lepsze zarządzanie awariami: Ceph jest zaprojektowany do zarządzania replikacją i redundancją danych na poziomie oprogramowania. Korzystanie z trybu HBA pozwala Ceph na lepsze zarządzanie awariami dysków i automatyczne przenoszenie danych w przypadku wykrycia problemów z dyskiem.
- Skalowalność: Tryb HBA ułatwia skalowanie klastra Ceph, ponieważ dodawanie nowych dysków lub węzłów jest prostsze i nie wymaga rekonfiguracji sprzętowej kontrolera RAID
3.2 Macierz mdadm
W trybie HBA nie będziemy mogli skonfigurować sprzętowej macierzy RAID, a chcemy takową tylko dla dysków systemowych, dlatego też w tym przypadku skorzystamy z programowej macierzy mdadm.
Podczas instalacji systemu Ubuntu Server z dwóch pierwszych dysków /dev/sda oraz /dev/sdb tworzymy RAID1 (Mirror). Pozostałe dyski muszą być czyste. Finalnie mamy następujący stan:
root@node1:~# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 372.6G 0 disk sdb 8:16 0 186.3G 0 disk ├─sdb1 8:17 0 1G 0 part /boot/efi └─sdb2 8:18 0 185.3G 0 part └─md0 9:0 0 185.1G 0 raid1 / sdc 8:32 0 186.3G 0 disk ├─sdc1 8:33 0 1G 0 part └─sdc2 8:34 0 185.3G 0 part └─md0 9:0 0 185.1G 0 raid1 / sdd 8:48 0 3.5T 0 disk sde 8:64 0 3.5T 0 disk sdf 8:80 0 3.5T 0 disk sdg 8:96 0 3.5T 0 disk sdh 8:112 0 3.5T 0 disk sdi 8:128 0 3.5T 0 disk sdj 8:144 0 3.5T 0 disk sdk 8:160 0 3.5T 0 disk sdl 8:176 0 3.5T 0 disk sdm 8:192 0 3.5T 0 disk nvme0n1 259:1 0 1.5T 0 disk
4. Synchronizacja czasu
Bardzo ważnym aspektem jest synchronizacja czasu na wszystkich nodach. Ceph Monitory (MON) są odpowiedzialne za utrzymanie stanu klastra i zarządzanie mapami monitorów. Działają one w oparciu o algorytm konsensusu Paxos, który wymaga precyzyjnej synchronizacji czasu. Nawet niewielkie odchylenia czasu mogą prowadzić do nieprzewidywalnego zachowania monitorów i problemów z konsensusem.
Pozostałe Demony Ceph wymieniają między sobą krytyczne wiadomości, które muszą być przetwarzane przed osiągnięciem progów czasowych. Brak synchronizacji czasu może prowadzić do przekroczenia tych progów i nieprawidłowego działania demonów.
W związku z tym instalujemy i konfigurujemy synchronizację czasu na wszystkich nodach:
apt install chrony -y systemctl enable --now chronyd timedatectl set-timezone Europe/Warsaw
5. Inicjalizacja klastra
W pierwszej kolejności na wszystkich nodach instalujemy dockera:
curl https://get.docker.com | bash
Następnie na node1.ceph.lab inicjalizujemy klaster Ceph w zależności od wersji którą chcemy zainstalować:
# instalujemy narzędzie cephadm apt install -y cephadm # ustawiamy wersję Ceph którą chcemy zainstalować cephadm add-repo --release reef # instalujemy cephadm install # ceph bootstrap cephadm bootstrap --mon-ip 172.20.0.101 --cluster-network 192.168.40.0/24 --allow-fqdn-hostname
Jeśli wszytko przebiegło bez problemów powinniśmy ujrzeć podsumowanie:
URL: https://node1.ceph.lab:8443/ User: admin Password: ********* Enabling client.admin keyring and conf on hosts with "admin" label Enabling autotune for osd_memory_target You can access the Ceph CLI as following in case of multi-cluster or non-default config: sudo /usr/sbin/cephadm shell --fsid 28ceaa61-cc7f-12ed-ac59-8f7d9832068a -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring Or, if you are only running a single cluster on this host: sudo /usr/sbin/cephadm shell Please consider enabling telemetry to help improve Ceph: ceph telemetry on For more information see: https://docs.ceph.com/en/pacific/mgr/telemetry/ Bootstrap complete.
Od tego momentu mamy dostęp do dashboard’u Cepha pod adresem: https://node1.ceph.lab:8443/
6. Dodawanie kolejnych hostów do klastra
Na hoście na którym jest uruchomiona usługa admina musimy mieć autoryzację po kluczach ssh do pozostałych nodów. W tym przypadku jest to node1.ceph.lab
ssh-keygen -q -N "" ssh-keyscan node1.ceph.lab node2.ceph.lab node3.ceph.lab node4.ceph.lab node5.ceph.lab node6.ceph.lab >> ~/.ssh/known_hosts ssh-copy-id -f -i /etc/ceph/ceph.pub [email protected] ssh-copy-id -f -i /etc/ceph/ceph.pub [email protected] ssh-copy-id -f -i /etc/ceph/ceph.pub [email protected] ssh-copy-id -f -i /etc/ceph/ceph.pub [email protected] ssh-copy-id -f -i /etc/ceph/ceph.pub [email protected] ssh-copy-id -f -i /etc/ceph/ceph.pub [email protected]
kolejnego noda możemy teraz dodać z GUI albo z CLI
6.1 Dodawanie hosta z CLI
Instalujemy ceph-common i dodajemy kolejne nody. ceph-common to pakiet zawierający zestaw narzędzi i bibliotek niezbędnych do interakcji z klastrem Ceph. Jest to kluczowy komponent dla użytkowników i administratorów, którzy chcą zarządzać i korzystać z rozproszonego systemu przechowywania Ceph.
# instalacja ceph-common cephadm add-repo --release quincy cephadm install ceph-common ceph -v # dodawanie noda: ceph orch host add node2.ceph.lab 172.20.0.102 ceph orch host add node3.ceph.lab 172.20.0.103 ceph orch host add node4.ceph.lab 172.20.0.104 ceph orch host add node5.ceph.lab 172.20.0.105 ceph orch host add node6.ceph.lab 172.20.0.106
7. Dodawanie OSD
W celu dodania dysku jako OSD trzeba się upewnić, że nie posiada on:
- żadnej partycji
- żadnego LVMa
- żadnego systemu plików
Sprawdzamy wszystkie dostępne dyski w całym klastrze:
ceph orch device ls
Dodajemy wszystkie dostępne dyski:
ceph orch apply osd --all-available-devices
Po uruchomieniu powyższego polecenia:
- Jeśli dodasz nowe dyski do klastra, zostaną one automatycznie użyte do utworzenia nowych OSD.
- Jeśli usuniesz OSD i wyczyścisz wolumin fizyczny LVM, nowe OSD zostanie utworzone automatycznie.
8. Tworzenie CephFS
CephFS (Ceph File System) to zgodny z POSIX system plików, zbudowany na bazie rozproszonego magazynu obiektów Ceph, znanego jako RADOS. CephFS zapewnia nowoczesne, wielozadaniowe, wysoce dostępne i wydajne środowisko do przechowywania plików, idealne dla różnych zastosowań, takich jak współdzielone katalogi domowe, przestrzeń scratch w HPC oraz rozproszone środowiska pracy. Kluczową cechą CephFS jest oddzielenie metadanych plików od danych plików, co umożliwia skalowanie poprzez klaster serwerów metadanych (MDS). Klienci mają bezpośredni dostęp do RADOS, co pozwala na liniowe skalowanie wydajności w miarę rozrostu klastra.
1. Tworzymy dwa poole na data i metadata
ceph osd pool create cephfs_data ceph osd pool create cephfs_metadata
2. Następnie tworzymy na nich zasób cephfs
ceph fs new cephfs cephfs_metadata cephfs_data
3. Sprawdzamy
ceph fs ls
Od tego momentu możemy montować system plików CephFS na dowolnej maszynie w sieci. Aby zamontować CephFS na systemie Linux, można użyć zarówno sterownika jądra, jak i narzędzia ceph-fuse.
Podsumowanie
Powyższy artykuł pokazuje jeden ze sposobów instalacji klastra Ceph. Rozpoczynając od instalacji niezbędnych pakietów i konfiguracji węzłów, artykuł prowadzi przez dodawanie dysków OSD, które są podstawowymi jednostkami przechowywania w Ceph. Następnie opisuje tworzenie pooli, które organizują dane w klastrze, oraz kończy na konfiguracji CephFS, systemu plików umożliwiającego dostęp do danych w sposób zbliżony do tradycyjnych systemów plików.
Klaster Ceph jest skomplikowany, ale jego złożoność jest uzasadniona przez oferowane korzyści. Ceph zapewnia niemal nieskończoną skalowalność, wysoką dostępność i elastyczność w zarządzaniu danymi, co czyni go idealnym rozwiązaniem dla dużych środowisk przechowywania danych. Jednakże, wdrożenie i utrzymanie klastra Ceph wymaga znacznej wiedzy technicznej i zaangażowania. Administracja Ceph może być wyzwaniem, szczególnie w kontekście konfiguracji, monitorowania i rozwiązywania problemów. Mimo to, narzędzia takie jak cephadm oraz wsparcie społeczności i dokumentacji znacznie ułatwiają zarządzanie klastrem Ceph.
Jeśli planujesz wdrożenie klastra Ceph w swojej organizacji, skontaktuj się z nami. Z chęcią podejmiemy się tego zdania.




