W obecnych czasach wysoka dostępność danych w firmach i organizacjach jest elementem kluczowym. Współczesne przedsiębiorstwa polegają na danych do podejmowania strategicznych decyzji, śledzenia trendów, obsługi klientów i zarządzania operacjami. Utrata dostępu do danych może prowadzić do poważnych konsekwencji, strat finansowych, zagrożenia bezpieczeństwa oraz utraty zaufania klienta. Dlatego też wybór elastycznego i dostępnego cenowo rozwiązania jest niezwykle ważny dla sukcesu organizacji. Jak zapewnić ciągłość działania i zabezpieczyć się przed awariami storage ?
SDS czyli storage o wysokiej dostępności: Część 1 przewodnik po rozwiązaniu GlusterFS.
W artykule omówimy, dlaczego Software Defined Storage (SDS), a w szczególności rozwiązanie GlusterFS, jest jednym z kluczowych narzędzi w zapewnianiu wysokiej dostępności danych.
Czym jest shared storage i SDS ?
Shared Storage (Współdzielona pamięć masowa) – jest to centralny zasób pamięci masowej, dostępny jednocześnie dla wielu serwerów lub węzłów w klastrze. W klastrach o wysokiej dostępności (HA) współdzielona pamięć masowa jest niezbędna. Pozwala na przechowywanie danych, które są dostępne dla wszystkich węzłów klastra jednocześnie, dzięki temu umożliwiając szybkie przełączanie się między węzłami w przypadku awarii jednego z nich. Bez współdzielonej pamięci masowej klastry HA nie mogą działać ponieważ dane z jednego węzła musiały by być w jakiś sposób transportowane do drugiego w przypadku awarii.
Software Defined Storage (SDS) – tradycyjna macierz dyskowa to urządzenie zawierające zbiór kilku dysków fizycznych, które są widziane przez system operacyjny komputera jako pojedynczy dysk logiczny. Oznacza to, że mamy jeden duży wirtualny dysk, który jest złożony z wielu fizycznych dysków. Natomiast Software Defined Storage (SDS) to nowoczesna architektura pamięci masowej w której do stworzenia pojedynczego dysku logicznego nie stosuje się osobnych urządzeń, a jedynie wydzieloną część zasobów serwerów. SDS wykorzystuje oprogramowanie do stworzenia i zarządzania pamięcią masową, która składa się z części dysków obecnych we wszystkich serwerach składających się na klaster HA. Takie rozwiązanie ma kilka istotnych zalet w porównaniu do tradycyjnych macierzy dyskowych:
- Elastyczność: SDS pozwala na dynamiczne dostosowywanie się do rosnących potrzeb bez konieczności zmiany sprzętu.
- Odporność na awarie: SDS może replikować dane na różnych węzłach, minimalizując ryzyko utraty danych.
- Skalowalność i Elastyczność: SDS pozwala na dynamiczne dostosowywanie się do rosnących potrzeb bez konieczności zmiany sprzętu. Wystarczy dołączyć kolejne serwery/węzły do klastra HA.
- Sprzęt nie jest związany z oprogramowaniem: SDS oddziela zarządzanie pamięcią masową od konkretnego sprzętu. To oznacza, że możemy korzystać z różnych dostawców sprzętu, a oprogramowanie SDS działa na nim w sposób niezależny.
- Otwarte standardy: Wiele rozwiązań SDS opiera się na otwartych standardach, co oznacza, że nie jesteśmy ograniczeni do jednego konkretnego dostawcy. Możemy dostosować naszą infrastrukturę do własnych wymagań.
- Dostępność cenowa: SDS jest często bardziej opłacalne niż tradycyjne macierze dyskowe.
W skrócie, SDS to bardziej elastyczne, wydajne i przystępne cenowo rozwiązanie w porównaniu do tradycyjnych macierzy dyskowych
Do czego służy GlusterFS ?
Obecnie na rynku istnieje wiele narzędzi do budowy SDS. Najpopularniejsze z nich to GlusterFS, Ceph, OpenIO czy LizardFS. Dzisiaj zajmiemy się pierwszym z nich.
GlusterFS to rozproszony system plików służący do budowania SDS, który łączy komponenty pamięci masowej z wielu serwerów w jedno, spójne środowisko. Działa w tle, a jego elastyczność i skalowalność sprawiają, że jest popularny w klastrach, chmurach i aplikacjach Big Data.
Za pomocą tego rozwiązania możemy stworzyć loginczy volumen na który będzie się składać wiele fizycznych dysków na każdym z serwerów w naszym klastrze.
GlusterFS umożliwia udostępnianie wolumenu za pomocą następujących protokołów:
- NFS (Network File System): Pozwala na montowanie wolumenu jako zasobu sieciowego na innych maszynach.
- CIFS / SMB (Server Message Block): Umożliwia dostęp do wolumenu z systemów Windows.
- Gluster Native Client: Umożliwia montowanie wolumenu na maszynach Linux.
Dzięki tym protokołom możemy udostępniać dane z wolumenu GlusterFS w różnych środowiskach.

GlusterFS powstał pierwotnie jako projekt Gluster, Inc., a następnie został przejęty przez Red Hat, Inc. w 2011 roku. Nazwa “Gluster” pochodzi od połączenia terminów GNU i cluster. Obecnie Red Hat jest głównym autorem i opiekunem projektu GlusterFS, ale rozwiązanie rozwijane jest na zasadach open source.
Zalety:
- Skalowalność: GlusterFS może rosnąć w miarę potrzeb, dodając nowe węzły do klastra.
- Prosta konfiguracja: Łatwość wdrożenia i zarządzania, szczególnie dla małych i średnich firm.
- Elastyczność: Oferuje różne tryby dostępu (bloki, obiekty, system plików), dostosowane do różnych zastosowań.
Wady:
- Wydajność: W niektórych przypadkach wydajność może być niższa niż w innych systemach.
- Złożoność sieciowa: Tworzenie i zarządzanie dużymi klastrami może wymagać zaawansowanej wiedzy sieciowej.
- Brak zaawansowanych funkcji: W porównaniu do niektórych innych SDS, GlusterFS może nie oferować tak zaawansowanych funkcji.
Podsumowując, GlusterFS jest elastycznym i skalowalnym rozwiązaniem, ale wymaga uwagi w kwestii wydajności i konfiguracji sieciowej.
Wymagania sprzętowe GlusterFS
Minimalne wymagania sprzętowe dla węzła GlusterFS z kilkoma dyskami SSD:
- Procesor: Minimum 2 rdzenie z procesorem o częstotliwości co najmniej 2,4 GHz.
- Pamięć RAM: Minimum 8 GB.
Ilość dodatkowych zasobów potrzebnych dla każdego następnego dysku SSD zależy od kilku czynników:
- Typ dysku SSD: Dyski SSD SATA wymagają mniej zasobów niż dyski SSD NVMe.
- Pojemność dysku SSD: Większe dyski SSD wymagają więcej zasobów niż mniejsze dyski SSD.
- Sposób użycia dysku SSD: Dyski SSD używane do przechowywania danych wymagają mniej zasobów niż dyski SSD używane do intensywnych operacji wejścia/wyjścia (I/O) np syki pod bazy danych.
Przykład:
Dodanie 1 TB dysku SSD SATA do puli pamięci GlusterFS może spowodować:
- Zwiększenie całkowitej pojemności puli pamięci o 1 TB.
- Zwiększenie zużycia CPU o 1-2%.
- Zwiększenie zużycia pamięci RAM o 100-200 MB.
Uwaga:
Powyższe wartości są jedynie orientacyjne. Rzeczywiste zużycie zasobów może się różnić w zależności od konkretnego zastosowania.
Założenia scenariusza testowego
Wykorzystamy GlusterFS do zbudowania SDS o wysokiej dostępności złożonego z trzech serwerów. Naszym celem jest zapewnienie dostępności storage, nawet gdy jeden z serwerów przestanie działać. Do tego celu wykorzystamy trzy serwery o adresacji IP jak poniżej. Dobrą praktyką jest przypisanie osobnych kart sieciowych z osobną adresacją tylko na potrzeby synchronizacji GlusterFS. W efekcie każdy węzeł będzie miał dwa adresy IP.
| Host | IP host | IP gluster |
| node1 | 192.168.140.244 | 10.225.38.244 |
| node2 | 192.168.140.245 | 10.225.38.245 |
| node3 | 192.168.140.246 | 10.225.38.246 |
Na każdym serwerze dostępne będą 4 dyski
- /dev/sda – dysk systemowy
- /dev/sdb – dysk na brick 1
- /dev/sdc – dysk na brick 2
- /dev/sdc – dysk na brick 3
Zakładamy że na wszystkich serwerach mamy następujący stan:
- aktualny system (Debian/Ubuntu)
- włączona synchronizacja czasu (chronyd lub ntpd). To bardzo ważne ! Znaczniki czasu muszą być identyczne.
- ustawione stałe adres IP jak w tabeli
Stan dysków i sieci wygląda następująco:
root@kamil-gluster-node1:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 5G 0 disk
├─sda1 8:1 0 4.9G 0 part /
├─sda14 8:14 0 3M 0 part
└─sda15 8:15 0 124M 0 part /boot/efi
sdb 8:16 0 2G 0 disk
sdc 8:32 0 2G 0 disk
sdd 8:48 0 2G 0 disk
sr0 11:0 1 4M 0 rom
root@kamil-gluster-node1:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether d2:c1:4c:a7:02:64 brd ff:ff:ff:ff:ff:ff
altname enp0s18
inet 192.168.140.244/24 brd 192.168.140.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::d0c1:4cff:fea7:264/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether ce:60:8e:00:30:80 brd ff:ff:ff:ff:ff:ff
altname enp0s19
altname ens19
inet 10.225.38.244/24 brd 10.225.38.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::cc60:8eff:fe00:3080/64 scope link
valid_lft forever preferred_lft forever
Tworzenie replikowanych woluminów
GlusterFS oferuje wiele różnych możliwości konfiguracji volumenów. Aby artykuł nie był za długi zajmiemy się tylko dwoma najpopularniejszymi: „Replicated Volumes” oraz „Distributed-Replicate Volumes„.
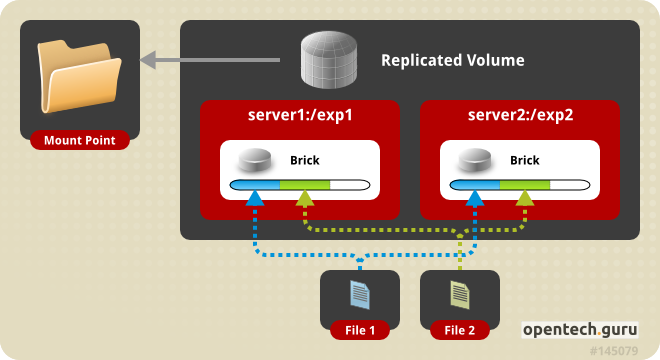
- Replicated volumes w GlusterFS tworzą kopie plików na różnych zestawach cegieł (tz. brick), aby zapewnić wysoką dostępność i wiarygodność. Ilość zestawów zwykle wynosi 3 czyli tyle ile ilość replik. Te typy volumów są szczególnie przydatne w środowiskach, w których wysoka dostępność i wiarygodność są kluczowe.
- Distributed-Replicate Volumes działa podobnie, ale rozdziela pliki w zreplikowanych blokach pomiędzy wiele zestawów cegieł.
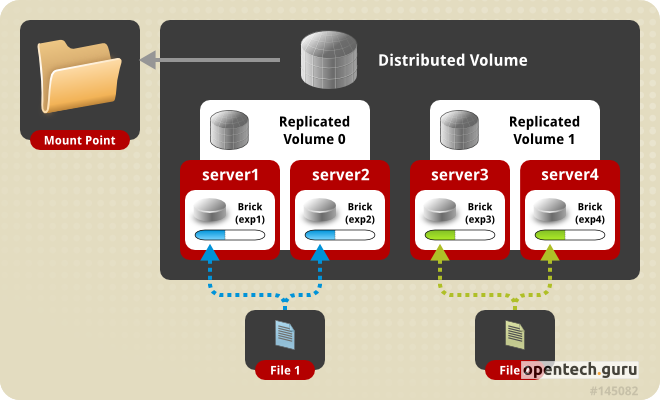
- Cegły (ang. bricks) czasami nazywane też blokami, to fizyczne dyski lub pliki, które są używane do tworzenia volumów. Cegły są elementami podstawowymi, na których opiera się architektura rozproszona GlusterFS. Każda cegła reprezentuje pewną część danych, która jest dostępna na konkretnym serwerze. Cegły mogą być lokalnymi dyskami fizycznymi lub plikami, które są montowane na serwerze GlusterFS.
Całą pracę zaczniemy od przygotowania naszych dysków. Dla każdego dysku tworzymy LVM oraz filesystem XFS.
Wykonujemy na wszystkich nodach:
# Tworzymy LVM'y pvcreate /dev/sdb pvcreate /dev/sdc pvcreate /dev/sdd vgcreate vg_sdb /dev/sdb vgcreate vg_sdc /dev/sdc vgcreate vg_sdd /dev/sdd lvcreate --name lv_sdb -l 100%vg vg_sdb lvcreate --name lv_sdc -l 100%vg vg_sdc lvcreate --name lv_sdd -l 100%vg vg_sdd # Tworzymy system plików. Gluster zaleca XFS mkfs -t xfs -f -i size=512 -n size=8192 -L GLUSTER_SDB /dev/vg_sdb/lv_sdb mkfs -t xfs -f -i size=512 -n size=8192 -L GLUSTER_SDC /dev/vg_sdc/lv_sdc mkfs -t xfs -f -i size=512 -n size=8192 -L GLUSTER_SDD /dev/vg_sdd/lv_sdd
Następnie montujemy dyski aby GlusterFS mógł stworzyć na nich brick’i:
mkdir -p /bricks/sdb mkdir -p /bricks/sdc mkdir -p /bricks/sdd vim /etc/fstab
dodajemy montowanie przez mappera:
/dev/mapper/vg_sdb-lv_sdb /bricks/sdb xfs defaults /dev/mapper/vg_sdc-lv_sdc /bricks/sdc xfs defaults /dev/mapper/vg_sdd-lv_sdd /bricks/sdd xfs defaults
mount -a
sprawdzamy
root@kamil-gluster-node1:~/bin# mount | grep /bricks/ /dev/mapper/vg_sdb-lv_sdb on /bricks/sdb type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota) /dev/mapper/vg_sdc-lv_sdc on /bricks/sdc type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota) /dev/mapper/vg_sdd-lv_sdd on /bricks/sdd type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota) root@kamil-gluster-node1:~/bin# df -h | grep /bricks/ /dev/mapper/vg_sdb-lv_sdb 2.0G 47M 1.9G 3% /bricks/sdb /dev/mapper/vg_sdc-lv_sdc 2.0G 47M 1.9G 3% /bricks/sdc /dev/mapper/vg_sdd-lv_sdd 2.0G 47M 1.9G 3% /bricks/sdd
Gdy już miejsce pod brick’i jest dostępne przystępujemy do instalacji samego GlusterFS oraz do połączenia ze sobą wszystkich serwerów w nomenklaturze GlusterFS nazywanych peer’ami
# instalacja apt-get install glusterfs-server glusterfs-client systemctl enable --now glusterd
Jeśli mamy włączonego firewalla musimy zezwolić na ruch sieciowy na odpowiednich portach w zależności od usług z jakich chcemy korzystać.
z pierwszego peer’a/serwera podłączamy drugiego i trzeciego peer’a
gluster peer probe 10.225.38.245 gluster peer probe 10.225.38.246
sprawdzamy stan klastra:
root@kamil-gluster-node1:~/bin# gluster peer status Number of Peers: 2 Hostname: 10.225.38.245 Uuid: d5d5843e-9c4e-4af9-9549-1295a88f6b58 State: Peer in Cluster (Connected) Hostname: 10.225.38.246 Uuid: e7f05637-8c80-454c-9f16-c4ca7cc8de7b State: Peer in Cluster (Connected)
Na koniec tworzymy replikowalny volumen o nazwie test_vol. W początkowej fazie nasz volumen będzie się składał tylko z 3 brick’ów. Następnie powiększymy go, rozszerzając o kolejne brick’i.
root@kamil-gluster-node1:~# gluster volume create test_vol transport tcp replica 3 10.225.38.244:/bricks/sdb 10.225.38.245:/bricks/sdb 10.225.38.246:/bricks/sdb force volume create: test_vol: success: please start the volume to access data root@kamil-gluster-node1:~# gluster volume start test_vol volume start: test_vol: success root@kamil-gluster-node1:~# gluster volume info test_vol Volume Name: test_vol Type: Replicate Volume ID: 24ea27a8-d855-4ca5-934e-16563ed13826 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: 10.225.38.244:/bricks/sdb Brick2: 10.225.38.245:/bricks/sdb Brick3: 10.225.38.246:/bricks/sdb Options Reconfigured: cluster.granular-entry-heal: on storage.fips-mode-rchecksum: on transport.address-family: inet nfs.disable: on performance.client-io-threads: off
Mamy stworzony replikowalny volumen składający się z trzech replik. Spróbujmy go zamontować i sprawdzić jego pojemność.
W pierwszej kolejności zezwalamy na montowanie zasobów GlusterFS z określonego IP:
root@kamil-gluster-node1:~# gluster volume set test_vol auth.allow 10.225.38.244 volume set: success
Następnie montujemy i sprawdzamy zasób:
root@kamil-gluster-node1:~# mount -t glusterfs 10.225.38.244:test_vol /mnt root@kamil-gluster-node1:~# df -h /mnt Filesystem Size Used Avail Use% Mounted on 10.225.38.244:test_vol 2.0G 67M 1.9G 4% /mnt
Teraz nasz volumen rozszerzymy o kolejne brick’i:
root@kamil-gluster-node2:~# gluster volume add-brick test_vol 10.225.38.244:/bricks/sdc 10.225.38.244:/bricks/sdd 10.225.38.245:/bricks/sdc 10.225.38.245:/bricks/sdd 10.225.38.246:/bricks/sdc 10.225.38.246:/bricks/sdd force volume add-brick: success root@kamil-gluster-node2:~# gluster volume info Volume Name: test_vol Type: Distributed-Replicate Volume ID: b1d0f4fb-1070-4562-b81c-d36f99840814 Status: Started Snapshot Count: 0 Number of Bricks: 3 x 3 = 9 Transport-type: tcp Bricks: Brick1: 10.225.38.244:/bricks/sdb Brick2: 10.225.38.245:/bricks/sdb Brick3: 10.225.38.246:/bricks/sdb Brick4: 10.225.38.244:/bricks/sdc Brick5: 10.225.38.244:/bricks/sdd Brick6: 10.225.38.245:/bricks/sdc Brick7: 10.225.38.245:/bricks/sdd Brick8: 10.225.38.246:/bricks/sdc Brick9: 10.225.38.246:/bricks/sdd Options Reconfigured: cluster.granular-entry-heal: on storage.fips-mode-rchecksum: on transport.address-family: inet nfs.disable: on performance.client-io-threads: off
Zauważmy, że teraz zmienił się typ volumenu z Replicate na Distributed-Replicate.
Sprawdzamy pojemność po rozszerzeniu:
root@kamil-gluster-node2:~# df -h /mnt Filesystem Size Used Avail Use% Mounted on 10.225.38.244:test_vol 5.9G 199M 5.7G 4% /mnt root@kamil-gluster-node2:~#
Konfiguracja quorum
W GlusterFS „quorum” odnosi się do minimalnej liczby aktywnych węzłów lub brick’ów wymaganych do podejmowania decyzji związanych z operacjami zapisu i odczytu. Jest to mechanizm zapobiegający sytuacji „split-brain”, gdzie różne części klastra mogą działać niezależnie, prowadząc do konfliktów danych. Poprzez kontrolowanie quorum, GlusterFS zapewnia integralność danych i spójność operacji w klastrze. Poniższe ustawienia pomagają zapewnić integralność danych i uniknąć problemów związanych ze „split-brain” poprzez kontrolowanie dostępu do zapisu w zależności od liczby aktywnych zestawów brick’ów.
gluster volume set test_vol network.ping-timeout 5 gluster volume set test_vol cluster.server-quorum-type server gluster volume set test_vol cluster.quorum-type fixed gluster volume set test_vol cluster.quorum-count 1
Obsługa bardzo dużych plików
Domyślnie GlusterFS ma pewne ograniczenie: wielkość pliku nie może przekraczać wielkości jednego brick’a. Aby rozwiązać ten problem został wprowadzony tak zwany „Sharding”.
Sharding dzieli pliki na mniejsze części, dzięki czemu można je rozmieścić w cegłach tworzących volumen. Po włączeniu shardingu pliki zapisane na volumenie są dzielone na części. Rozmiar elementów zależy od wartości parametru features.shard-block-size volumenu. Pierwszy fragment jest zapisywany w cegle i otrzymuje identyfikator GFID jak zwykły plik. Kolejne elementy są równomiernie rozmieszczone pomiędzy cegłami w objętości (domyślnie rozmieszczone są cegły podzielone na kawałki), ale są zapisywane w katalogu .shard tej cegły i nazywane są za pomocą identyfikatora GFID oraz liczby wskazującej kolejność elementów.
Włączanie shardingu:
gluster volume set test_vol features.shard enable
Sprawdzamy czy to faktycznie działa
W pierwszej kolejności sprawdzamy stanu zdrowia volumenu:
root@kamil-gluster-node2:~# gluster volume heal test_vol info Brick 10.225.38.244:/bricks/sdb Status: Connected Number of entries: 0 Brick 10.225.38.245:/bricks/sdb Status: Connected Number of entries: 0 Brick 10.225.38.246:/bricks/sdb Status: Connected Number of entries: 0 Brick 10.225.38.244:/bricks/sdc Status: Connected Number of entries: 0 Brick 10.225.38.244:/bricks/sdd Status: Connected Number of entries: 0 Brick 10.225.38.245:/bricks/sdc Status: Connected Number of entries: 0 Brick 10.225.38.245:/bricks/sdd Status: Connected Number of entries: 0 Brick 10.225.38.246:/bricks/sdc Status: Connected Number of entries: 0 Brick 10.225.38.246:/bricks/sdd Status: Connected Number of entries: 0
W powyższym przykładzie widzimy, że wszystkie pliki są zsynchronizowane poprawnie oraz wszystkie brick’i są dostępne.
Na potrzeby testu stworzymy mały plik TXT z pewną zawartością:
root@kamil-gluster-node1:/mnt# echo "test1 glusterfs" >/mnt/test1.txt root@kamil-gluster-node1:/mnt# cat /mnt/test1.txt test1 glusterfs
Następnie wyłączymy całkowicie node1 i sprawdzimy stan klastra oraz dostępność danych na węźle node2
root@kamil-gluster-node2:~# gluster volume heal test_vol info Brick 10.225.38.244:/bricks/sdb Status: Transport endpoint is not connected Number of entries: - Brick 10.225.38.245:/bricks/sdb Status: Connected Number of entries: 0 Brick 10.225.38.246:/bricks/sdb Status: Connected Number of entries: 0 Brick 10.225.38.244:/bricks/sdc Status: Transport endpoint is not connected Number of entries: - Brick 10.225.38.244:/bricks/sdd Status: Transport endpoint is not connected Number of entries: - Brick 10.225.38.245:/bricks/sdc Status: Connected Number of entries: 0 Brick 10.225.38.245:/bricks/sdd Status: Connected Number of entries: 0 Brick 10.225.38.246:/bricks/sdc Status: Connected Number of entries: 0 Brick 10.225.38.246:/bricks/sdd Status: Connected Number of entries: 0 root@kamil-gluster-node2:~# cat /mnt/test1.txt test1 glusterfs
3 brick’i są niedostępne, ale w tym samym momencie cały czas mamy dostęp do danych na volumenie test_vol zamontowanym w /mnt.
Podsumowanie
Jak widzisz GlusterFS to rozproszony system plików, który pozwala na budowę elastycznych, skalowalnych i wysoko dostępnych rozwiązań Software Defined Storage (SDS) w oparciu o tradycyjne serwery.
Oferuje możliwość tworzenia replikowanych woluminów, które kopiują pliki na różnych zestawach cegieł (brick’ów), aby zapewnić wysoką dostępność i wiarygodność.
Obsługuje także bardzo duże pliki poprzez segmentowanie ich na mniejsze fragmenty, które są rozpraszane po wszystkich węzłach klastra.
Skalowalność GlusterFS pozwala na dynamiczne dostosowywanie się do rosnących potrzeb bez konieczności zmiany sprzętu.








